
Jak się robi Data Science ? – czyli dzień z pracy badaczki danych
Autor : Angelika Olejczak
Seria : Kobieta w IT

Myślę że prędzej czy później trafiłabym do Data Science – z takim przekonaniem mówi o sobie Daria Hlibova, pracująca na co dzień jako Data Scientist w ING Banku Śląskim w Katowicach. To bardzo utalentowana, a jednocześnie niezwykle skromna, młoda kobieta mówiąca biegle w 4 językach, uwielbiająca sport, a przede wszystkim z ogromną pasją do danych, w których od 5 lat porusza się z naturalną zwinnością.
Co robi w wielkim świecie danych, do którego trafiła jak sądzi nie przez przypadek? Dowiedzcie się sami.
Krótko jak to się stało, że trafiłaś do tego zawodu co Ci się w nim spodobało?
Nie mogę powiedzieć, że trafiłam do tego zawodu przez przypadek, ponieważ studiowałam Informatykę i Ekonometrię i już w trakcie studiów wiedziałam czym chciałabym się zajmować w przyszłości. Myślę że też prędzej czy później trafiłabym do Data Science, ponieważ od dzieciństwa lubiłam nauki ścisłe, zawsze podobało mi się obliczanie różnych rzeczy, liczby i przeprowadzanie analiz. – wspomina Daria.
Na początku pracowałam jako Młodszy Specjalista ds. Raportowania z danymi i robiłam mniej oraz bardziej złożone analizy za pomocą języków SAS 4GL i R. Już od początku byłam zachwycona budową modeli predykcyjnych, interaktywną wizualizacją danych, podejmowaniem decyzji biznesowych opartych na danych. Dalsza praca z danymi tylko inspirowała mnie i motywowała do rozwoju w tej dziedzinie.
Jakie typowe zadania należą do Twoich obowiązków jako Data Scientistki?
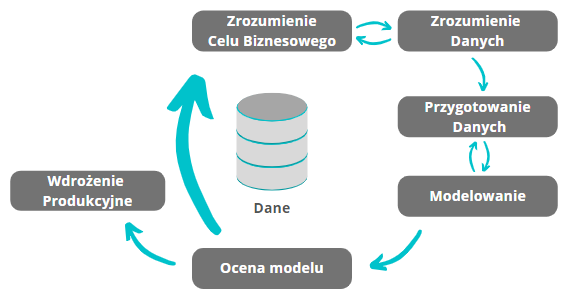
Typowym zestawem zadań w każdym moim projekcie jest:
- Pierwsza analiza, zrozumienie danych wejściowych oraz celu całego przedsięwzięcia, czyli tego co powinniśmy zrozumieć na podstawie danych i jak pozyskać te informacje.
- Wstępne przetwarzanie danych. Trzeba określić typy danych z jakimi mamy do czynienia i w zależności od tego, jeżeli projekt jest oparty na danych tabelarycznych/numerycznych to analizuję i wybieram najważniejsze zmienne. Gdy pracuję z kolei na danych tekstowych to konieczne jest oczyszczenie tekstu z niepotrzebnych znaków, błędów językowych itp. oraz wybór metody którą słowa będą transformowane na zrozumiałe dla komputera struktury numeryczne – tokeny. Jeżeli moje dane to obrazy to takim krokiem jest usunięcie szumu (niepożądanych elementów zniekształcających obraz np. kreski, kropki) z obrazów, stosowanie różnych metod przetwarzania obrazów jak np. stosowanie filtrów czy zmniejszenie ich rozmiarów.
- Dopiero gdy wstępnie przeprocesuję dane zaczynam budować model – czyli mechanizm uzyskiwania z danych wcześniej założonych informacji działający iteracyjnie według wybranej metody matematycznej. Istnieje wiele metod do pracy z danymi i spełniają różne funkcje jak np. : grupowanie, klasyfikowanie (np. tekstu lub pojedynczych cech obiektu opisanego tabelą), wyszukiwanie elementów na obrazku itp. Model „uczy się” konkretnego zjawiska opisanego danymi i pomaga wyłuskać z nich potrzebne informacje np. pogrupować tekst wykazywania pozytywnych lub negatywnych emocji przed piszącego na treningowej próbce danych – która jest pewnym wycinkiem z całości dostępnych informacji. Następnie porównuję zastosowane metody i algorytmy na podstawie wyników jakie uzyskuje na próbce testowej – która nie jest pokazywana modelowi w procesie uczenia, a sprawdza jego jakość i efektywność na nowej puli danych.
- Na końcu zawsze jest testowanie i ewentualnie tzw. „debugowanie” kodu – czyli poprawa błędów w przetwarzaniu modelu, wdrożenie modelu (co może być najtrudniejsze) oraz stworzenie mechanizmu do monitoringu, który kontroluje czy model utrzymuje wytrenowaną dokładność i czy nowe dane, które są przez niego procesowane zachowują te same cechy i opisują te samo zjawisko, na których budowaliśmy model. W innym wypadku, gdy zmienia nam się rzeczywistość opisywanego zjawiska, a co za tym idzie zmieniają się też dane z nim związane dla skorygowania ewentualnych błędów predykcji co jakiś okres warto douczać ten model.
Jakie nietypowe zadania mogą się również trafić, gdzie Twój udział jest niezbędny?
Wiemy ze statystyki że dane mogą być zarówno ustrukturyzowane jak i całkowicie nieuporządkowane. Prawda jest taka, że częściej dostajemy nieustrukturyzowane dane, które potrzebujemy uporządkować, żeby przejść do kolejnego kroku analizy. Też nie zawsze dane mogą mieć swoje etykiety (np. dane z tabeli o samochodach mogą mieć etykietę: osobowy / ciężarowy – jako opis rodzaju samochodu), więc data scientist musi znaleźć szybką i efektywną metodę żeby wszystkie dane posiadały swoje etykiety, potrzebne do zrealizowania przez model postawionego celu (w podanym przykładzie np. klasyfikacji danego pojazdu do odpowiedniej kategorii, by system mógł dokonać automatycze płatności za bramki na autostradzie). Czasami to może być oznakowanie danych przez ręczne nadanie im etykiet lub inna metoda statystyczna lub matematyczna. Innym równie ważnym elementem w pracy jest umiejętność zrozumiałego przedstawienia wyników analizy/modelu predykcyjnego, żeby ludzie którzy nie pracują na co dzień z tym zestawem danych i zjawiskiem mogli zrozumieć, co autor (analizy) miał na myśli, co chce przedstawić i przekazać odbiorcom, a przede wszystkim jakie wnioski dla nich płyną z tych analiz.
Jakich narzędzi używasz w pracy oraz do czego je stosujesz?
Nasze życie to są dane, więc musimy nauczyć się jak z nimi rozmawiać, żeby je zrozumieć. Do tego służą nam języki programowania. Na początku najbardziej wykorzystywałam język programowania R, teraz już w całości korzystam z Pythona. Język SQL, który służy do wydobywania, modyfikacji danych w relacyjnych bazach danych jest mi także niezbędny w codziennej pracy.
Czy możesz opisać jedno zadanie lub projekt, który najwięcej Cię nauczył? Jakie miałaś tam wyzwania i jakie wnioski do dalszej pracy wyciągnęłaś?
Realnym wyzwaniem była dla mnie praca z danymi tekstowymi oraz obrazkami, ponieważ nie są to klasyczne, tabelaryczne dane, gdzie można zastosować standardowe rozwiązania, nawet takie które wykorzystywałam czy stworzyłam wcześniej. W każdym projekcie są inne dane, które przed modelowaniem warto dokładnie przeanalizować i zrozumieć. – przyznaje Daria.
Wdrażanie modeli oraz komunikacja z innymi narzędziami też jest bardzo ważnym aspektem mojej pracy, który pokazuje że praca z danymi to nie tylko budowanie modeli, ale też wiedza o tym jak sprawić, by model skutecznie i sprawnie technicznie działał produkcyjnie, a nie był po prostu ćwiczeniem laboratoryjnym nie przynoszącym potencjalnym użytkownikom żadnych korzyści i zysku.
Aby zapobiec takim rozczarowaniom niejednokrotnie przekonałam się, że już na etapie wstępnej analizy danych i definiowania celu modelu predykcyjnego / analizy warto rozpatrzeć kilka przypadków możliwości wdrożenia takiego modelu do środowiska biznesowego. Jeśli z jakiś powodów dość szybko zidentyfikujemy poważne zagrożenia i blokady we wprowadzeniu naszego rozwiązania na przysłowiową „produkcję” jak np. brak ciągłości w dostarczaniu przepływów danych lub brak integralności istniejących aplikacji firmy z naszym kodem – możemy szybko przedefiniować realizowane zadanie lub w skrajnym przypadku nawet z niego zrezygnować, by nie tracić czasu i zasobów na pracochłonne analizy, kodowanie i testy algorytmu, który realnie i tak nie zadziała w biznesie.
Daria imponuje swoją rozległą wiedzą i praktycznym doświadczeniem, dlatego można by tu napisać z pewnością o wiele więcej. Jednak ciekawe, co myśli o samej roli kobiety w zawodzie Data Scientistki.
Na podstawie Twoich obserwacji czy kobiety sprawdzają się w takim zawodzie równie dobrze jak mężczyźni?
Myślę, że nie ma żadnej różnicy kim jesteś: kobietą lub mężczyzną. Ważne że masz pasję do danych, chcesz się rozwijać w tym kierunku, interesujesz się nowymi technologiami i nie boisz się spróbować czegoś nowego, nawet jeżeli te nowe zupełnie niewiadome.
Co byś powiedziała kobietom, które zastanawiają się czy porzucić swoją pracę i przekwalifikować się do zawodów związane z IT?
Myślę, że warto próbować! Warto szukać siebie, nie bać się popełnić błędu i wszystko wyjdzie. Moim zdaniem to jest tylko stereotyp, że mężczyźni są lepsi w takich mocno analitycznych zawodach. Kiedyś ktoś to wymyślił i tak się to przyjęło. – przyznaje z uśmiechem Daria. Chciałam dodatkowo zachęcić wszystkie z Was, które jeszcze się wahają, aby próbowac swoich sił w róznych spotkaniach branżowych związanych z analizą danych, maratonach programowania z Data Science (hackatonach), aby sprawdzić czy to jest coś co nas kręci, czy się do tego nadajemy, a także by po prostu poznać ludzi o podobnych zainteresowaniach i nawiązać cenne zawodowe kontakty.

Ale w dzisiejszych czasach sytuacja się zmienia i coraz więcej kobiet pracuje w IT. Ten fakt też inspiruje i motywuje do dalszego rozwoju swoich umiejętności w tej dziedzinie.
A dla tych, którzy już załapali zajawkę na Data Science lub są w trakcie podróży…
Może też dodałabym coś o tym, że warto być na bieżąco z nowymi technologiami, czytać o nowych metodach i algorytmach. Ponieważ świat Data Science się zmienia bardzo szybko i to co było aktualne rok temu teraz może być już zastąpione czymś innym.
Daria Hlibova jest świetnym przykładem na sukces, który może osiągnąć każdy zawsze i wszędzie pod warunkiem, że tego chce.
Może ktoś z Was skusi się na rozpoczęcie kursu nt. Data Science lub stworzy swój pierwszy wykres w Python po przeczytaniu tego artykułu. Hmm? 😉


