
Wyrażenia regularne w przeszukiwaniu tekstu
Autor: Radosław Weychan
Wyrażenia regularne. Brzmi strasznie, nieprawdaż? Jak enigmatyczne, matematyczne zapisy dowodów twierdzeń, pełne dziwnych znaczków, których znaczenie znają tylko nieliczni. I owszem, wyrażenia regularne są pełne znaczków, są jednak znacznie prostsze do zrozumienia niż mogłoby się wydawać. Mówię to jako były pracownik uczelni technicznej, który ma już „lekką” awersję do matematycznych zapisów.
Co to jest wyrażenie regularne?
Wyrażenia regularne to opis pewnego wzorca, którego szukamy w tekście. Co może być tym wzorcem? Na przykład data 21.07.2020 – są to cyfry z pewnego zakresu oddzielone kropkami. Wzorcem może być także ciąg liczb, które wylosowane zostały w Lotto: 2,4,22,26,31,35. Wzorcem można opisać adres email, adres strony internetowej czy oczekiwane znaki w haśle do konta bankowego. Wzorcem jest także fakt, iż każde nowe zdanie po kropce zaczynamy z dużej litery. Wzorcem można opisać wszystko co jest w jakiś sposób powtarzalne, a wyrażenia regularne pomagają nam znaleźć w tekście ciąg znaków pasujący do tego wzorca.
Koncepcja automatu wyszukującego pasujący ciąg znaków w tekście znana jest od lat 50 XX wieku. Jedna z pierwszych implementacji napisana była w języku SNOBOL – z naszego punktu widzenia nazwa nieco nietrafiona.
Przejdźmy do tematu wpisu, czyli do wykorzystania wyrażeń regularnych w przeszukiwaniu tekstu. Wyrażenia regularne są zwykle używane w skomplikowanych systemach informatycznych do wyszukiwania i dalszego przetwarzania ciągów znaków, które Kowalskiemu raczej niewiele powiedzą, oraz do walidacji (sprawdzenia poprawności) tekstu wpisanego przez użytkownika. Czy mogą się przydać w codziennym użyciu? A i owszem.
Pierwsze szukanie
Załóżmy, że przeszukujemy stronę https://pl.wikipedia.org/wiki/XVIII_wiek w poszukiwaniu osób, które urodziły się jeszcze w XVII wieku i żyły do minimum lat dwudziestych wieku XVIII. Po wyszukaniu na stronie tekstu „16” mamy ponad 100 wyników – powodzenia w przeglądaniu wszystkiego … Jak to zrobić? No właśnie, wyrażenia regularne! No dobra, tylko gdzie ich użyć?
Najprostszym rozwiązaniem jest wykorzystanie strony www.regex101.com. Wklejamy tam całą zawartość strony wikipedii (ctrl+a, ctrl+c, ctrl+v) w pole „TEST STRING”, a w pole „REGULAR EXPRESSION” wpisujemy wyrażenie regularne. Po prawej stronie otrzymamy wyniki szukania w polu „MATCH INFORMATION” – możemy kliknąć na wynik, a on przeniesie nas do miejsca w tekście.
Skoro już skopiowaliśmy całą stronę, czas wpisać wyrażenie regularne! Podam teraz rozwiązanie i opiszę je skąd co i jak:
16[0-9] {1,2} –17[2-9] [0-9]
Oto wynik:
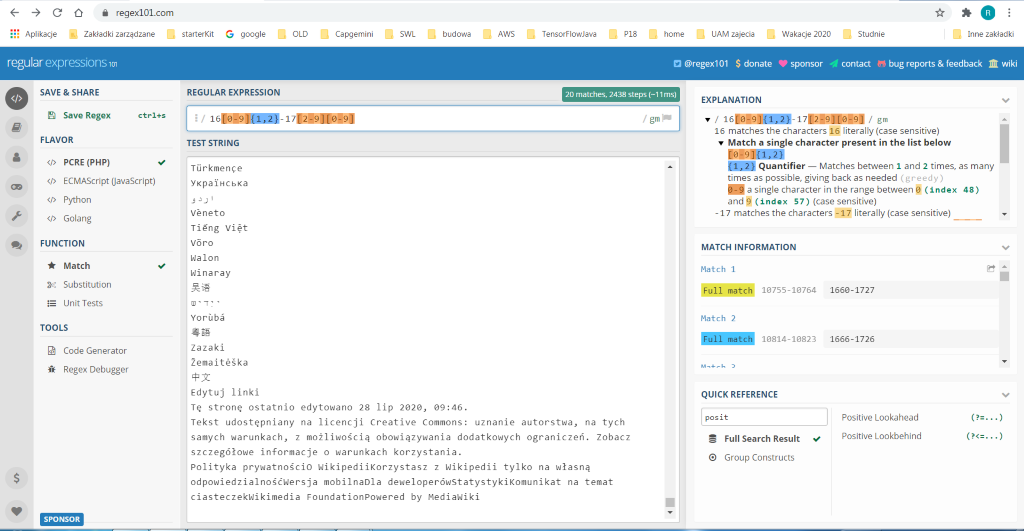
Fot. Pierwsze szukanie
20 wyników! Powodzenia w poszukiwaniu tego ręcznie…
Teraz wyjaśnienie – o co chodzi w 16[0-9]{2} -17[2-9] [0-9]? Wyjaśnijmy po kolei, częściami:
- 16 – szukany ciąg znaków musi zaczynać się od 16. W końcu szukamy wszystkiego co było w XVII wieku
- [0-9] {1,2} – w nawiasach kwadratowych jakiego pojedynczego znaku oczekujemy w następnej kolejności. Tu szukamy cyfr między 0 a 9. [a-z] oznacza, że szukamy małych liter od „a” do „z”. [a-zA-Z] oznacza, że szukamy małych i dużych liter „a” do „z”. [a-z0-9] oznacza, że szukamy małych liter „a” do „z”, oraz cyfr 0 do 9. [abc] oznacza, że szukamy tylko liter „a”, „b” lub „c”. W nawiasie klamrowym wpisujemy, ile razy ma się dany znak powtarzać – {2} oznacza między 2 powtórzenia (bo chcemy 2 cyfry po „16”, np. 1625). {0,2} oznacza między 0 a 2 powtórzenia. {3,} oznacza 3 i więcej powtórzeń
- -17 – po dacie np. 1625 oczekujemy „-17”, bo szukamy czegoś w rodzaju „1625-1725”
- [2-9] – w XVIII wieku interesuje nasz wszystko co było powyżej lat dwudziestych, czyli np. 1724, 1735, 1798. Na miejscu dziesiątek oczekujemy cyfr 2 do 9
- [0-9] – cyfra jednostek jest nieistotna, dlatego może to byś jakakolwiek cyfra między 0 a 9
Teraz poszukajmy wszystkich słów:
[a-zA-Ząęźćżłóń]+
5641 znalezionych! Sporo liczenia … Wyjaśnienie:
- [a-zA-Ząęźćżłóń] – znajdź wszystkie małe i duże litery, w tym polskie znaki
- + – bardzo ważny znak. Oznacza, że dany ciąg/znak ma się powtórzyć 1 lub więcej razy. W ten sposób znalezione też np. „III”, co jest na tym etapie niełatwe do uniknięcia
Znajdźmy wszystkie miejsca, gdzie jest wspomniany lipiec lub luty:
lipc[a-z] *|lut[a-z] *
23 wystąpienia! Wyjaśnienie:
- lipc[a-z] * – oznacza „lipc” i jakiekolwiek inne litery, żeby dopasować do lipiec, lipca, lipcowi itp.
- | – oznacza „lub”. Szukamy czegoś „lub” czegoś
- lut[a-z] * – oznacza „lut” i jakiekolwiek inne litery, aby dopasować luty, lutego, lutemu itp.
Czas wypłynąć na głębsze wody
A teraz przejdźmy do przeszukania historii Polski:
https://pl.wikipedia.org/wiki/Polska
Znajdźmy wszystkie akapity, w których jest wzmianka o królu, oraz które dotyczą XVIII i XIX wieku. Zadanie to można zrobić na dwa sposoby:
- możemy określić występowanie dat w danym akapicie przed lub po słowie król
- możemy skorzystać z nowej formuły szukania w przód z wynikiem pozytywnym (ang. Positive lookahead)
Rozszyfrujmy pierwszy przypadek:
^. *(1[7-8] [0-9]{2} )?. *[Kk]ról. *(1[7-8] [0-9]{2} )?.*$
Oj robi się skomplikowanie. Na tyle, że komputer, który obsługuje tę stronę internetową, nie jest w stanie sobie poradzić w sensownym czasie z tym problemem, dlatego też operacja została przerwana. Ale nic straconego – możemy spróbować zrobić to bezpośrednio na naszym komputerze. Do tego potrzebujemy edytor tekstu, który wspiera wyrażenia regularne, np. Notepad++. Po jego instalacji, kopiujemy zawartość strony internetowej w ten sam sposób jak poprzednio, wklejamy do edytora, używamy skrótu klawiszowego CTRL+F, po czym naszym oczom ukazuje się okienko wyszukiwania:
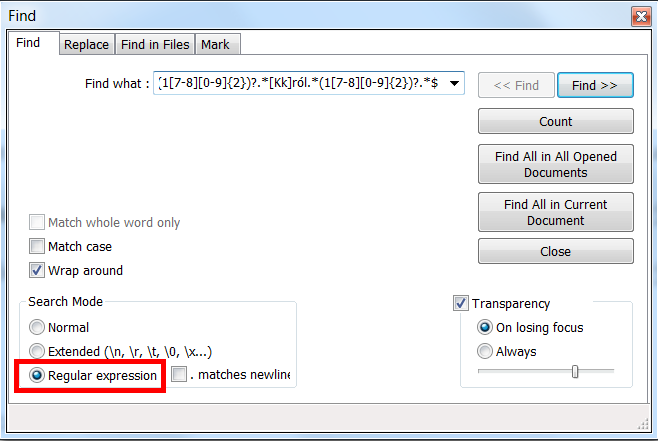
Fot. Wyszukiwanie w programie Notepad++
W polu „Search mode” musimy wybrać tylko opcję „Regular expression”, następnie wkleić wyrażenie i na początek wcisnąć przycisk „Count”, czyli „Policz”. Po kilku chwilach mamy wynik: 30! Przeanalizujmy to wyrażenie i zobaczmy, czy na pewno dostaniemy to czego chcemy:
- ^ – oznacza początek linii. Szukamy treści zaczynających się od nowej linii
- . * – wyszukaj wszystko, co nie jest przejściem do kolejnej linii. Nie oczekujemy bowiem, że data czy słowo „król” będzie od razu na samym początku
- (1[7-8] [0-9]{2})? – to wyrażenie musimy przeanalizować bardziej szczegółowo:
- 1[7-8] [0-9]{2} – szukamy zestawy cyfr, gdzie pierwsza to 1, druga to 7 lub 8 (bo XVIII lub XIX wiek), następnie dowolna cyfra w liczbie dwóch (w nawiasach klamrowych określamy liczbę powtórzeń)
- ()? – powyższy ciąg cyfr zamknięty został w nawiasy. Oznacza to, że będzie to pewna grupa, dla której określimy także inne cechy szukania. W tym przypadku jest to znak zapytania „?”. Oznacza on, że cała grupa jest opcjonalna – może wystąpić, ale nie musi. Innymi słowy, szukamy daty, ale nie musi ona wystąpić (w tym przypadku przed słowem „król”, o czym za chwilę)
- . *[Kk]ról. * – w następnej kolejności szukamy słowa „król” (pisany z dużej lub z małej litery), poprzedzony dowolnymi znakami, a także po którym mogą występować dowolne znaki. Podsumowując aktualny stan: Szukamy słowa „król”, przed którym może pojawić się data z zakresu XVIII lub XIX wieku. Między datą, jeśli takowa została znaleziona, a słowem „król”, mogą znajdować się dowolne znaki (oprócz znaku nowej linii)
- (1[7-8] [0-9]{2})? – i znowu, po słowie „król” może znajdować się data z zakresu XVIII i XIX wieku
- . * – po dacie, jeśli takowa została znaleziona, mogą wystąpić dowolne znaki …
- $ – … których szukamy, aż do momentu pojawienia się znaku końca linii
Czy jednak jest to poprawne wyrażenie? Jeśli w naszym nowym notatniku klikniemy dwukrotnie przycisk „Find”, wskaże on następującą linię jako pasującą do wzorca:
Bolesław I Chrobry, pierwszy król Polski
Ale chwila, przecież tu nie ma daty! No właśnie – obie daty, zarówno przed słowem „król” oraz po nim, określiliśmy jako opcjonalne – może ich wcale tam nie być! Czy można zatem tak rozszerzyć ten wzorzec, by jednak wymuszał znalezienie daty przed albo po słowie „król”? Można, ale nawet bardziej edytować niż rozszerzyć, albowiem powyższy wzorzec stał się już nieco nieczytelny. Z pomocą przychodzi właśnie szukanie w przód z wynikiem pozytywnym.
Przeanalizujmy teraz nową składnię do szukania w przód:
^(? =. *1[7-8] [0-9]{2}. *). *[Kk]ról. *$
- ^ – podobnie jak poprzednio, zaczynamy szukanie wśród fragmentów tekstu zaczynającego się od nowej linii
- (? =. *1[7-8] [0-9]{2}. *) – rozbijmy to wyrażenie celem dalszej analizy:
- . *1[7-8] [0-9]{2}. * – szukamy daty z XVIII lub XIX wieku, poprzedzonej dowolnymi znakami, oraz po której mogą być także dowolne znaki. Nie precyzujemy, gdzie względem słowa „król” ma znajdować się data
- (? =) – oto właśnie składnia szukania w przód z wynikiem pozytywnym – szukamy daty gdziekolwiek pomiędzy znakiem nowej linii ^, a znakiem końca linii $
- . *[Kk]ról. * – w następnej kolejności szukamy słowa „król” (pisany z dużej lub z małej litery), poprzedzony dowolnymi znakami, a także po którym mogą dowolne znaki. Podsumowując, szukamy całego ciągu znaków ze słowem „król” pod warunkiem, że jest w tym ciągu także data z XVIII lub XIX wieku.
Ile mamy teraz wyników? Możemy to już sprawdzić w przeglądarce internetowej – tym razem tylko 8. Sprawdź czy na pewno wszystkie się zgadzają. Nie może być inaczej 🙂
Oprócz szukania w przód z wynikiem pozytywnym, są jeszcze 3 inne podobne formuły. Zestawmy poniżej wszystkie cztery (w każdym z nim trzykropek oznacza wyszukiwane wyrażenie):
- (?=…) – szukanie w przód z wynikiem pozytywnym
- (?!…) – szukanie w przód z wynikiem negatywnym
- (? <=…) – szukanie w tył z wynikiem pozytywnym
- (?<!…) – szukanie w tył z wynikiem negatywnym
Zachęcam do samodzielnego wykorzystania pozostałych trzech.
Na koniec chciałbym jeszcze pokazać rozwiązanie pewnego błahego problemu – często w tekście nie wiemy, gdzie się kończy nawias, zwłaszcza jeśli tekstu w nawiasie jest naprawdę sporo. Owszem, możemy przez zwykłe CTRL+F wyszukać zamknięcia, ale jeśli jest ono daleko, tracimy z oczu znowu nawias otwierający.
Przeanalizujmy problem na prostym przykładzie:
„Polska, Rzeczpospolita Polska (RP) – państwo unitarne w Europie Środkowej, położone między Morzem Bałtyckim na północy a Sudetami i Karpatami na południu, w przeważającej części w dorzeczu Wisły i Odry. Od północy Polska graniczy z Rosją (z jej obwodem kaliningradzkim) i Litwą, od wschodu z Białorusią i Ukrainą, od południa ze Słowacją i Czechami, od zachodu z Niemcami. Większość północnej granicy Polski wyznacza wybrzeże Morza Bałtyckiego. Polska Wyłączna Strefa Ekonomiczna na Bałtyku graniczy ze strefami Danii i Szwecji. Granice z Ukrainą, Białorusią i Rosją stanowią równocześnie granicę zewnętrzną Unii Europejskiej i strefy Schengen.”
Jak będzie wyglądał wzorzec na wyszukiwanie wyrażeń w nawiasach? (WAŻNE! – działa on tylko w przypadku, gdy nawiasy nie są zagnieżdżone; jeśli są, potrzebujemy dużo bardziej skomplikowanych wzorców, które jednak teraz namąciłyby w głowie. Oczywiście potrzebujemy na pewno dwóch znaków – otwarcia i zamknięcia nawiasu, oraz określenia co ma być między nimi. Zacznijmy od:
\(.*\)
I spróbujmy zaaplikować ten wzorzec na powyższym tekście na stronie www.regex101.com.
I co się stało? Owszem znalazło, ale pierwsze otwarcie nawiasu i ostatnie zamknięcie. I pokazało jako wynik wszystko pomiędzy. A dlaczego tak? Otóż dlatego, że wyrażenia regularne są z reguły „zachłanne” – biorą jako wynik jak najwięcej się da. Innymi słowy, algorytm znalazł pierwszy nawias zamykający, ale szukał dalej, no i znalazł. Jest zachłanny, zatem wziął wszystko co definiuje fragment.*. Jak w takim razie sprawić, żeby algorytm nie był zachłanny? Dodaniem w odpowiednim miejscu operatora niezachłanności? :
\(.*?\)
I w ten prosty sposób możemy od razu skopiować całą zawartość nawiasu, bez szukania, gdzie jest jego koniec.
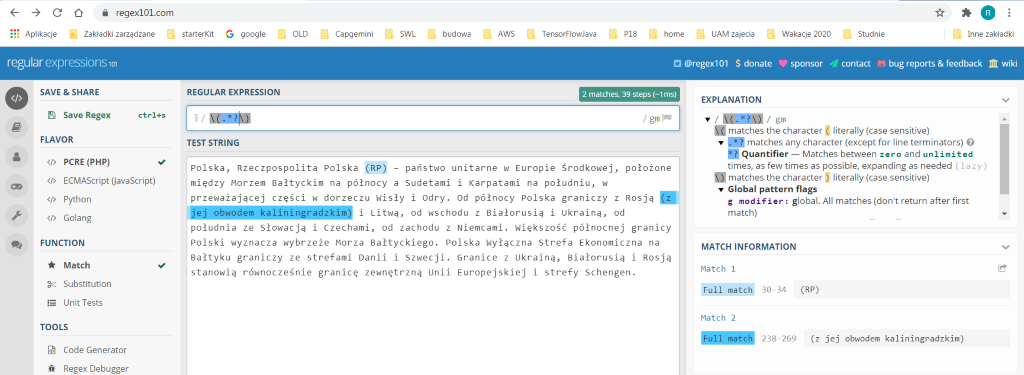
Fot. Wyszukiwanie zawartości nawiasów.
